Cluster
Overview
The full documentation of all configuration options is in the cluster role documentation. For general configuration, have a look at the common role documentation.
Overview
Cluster
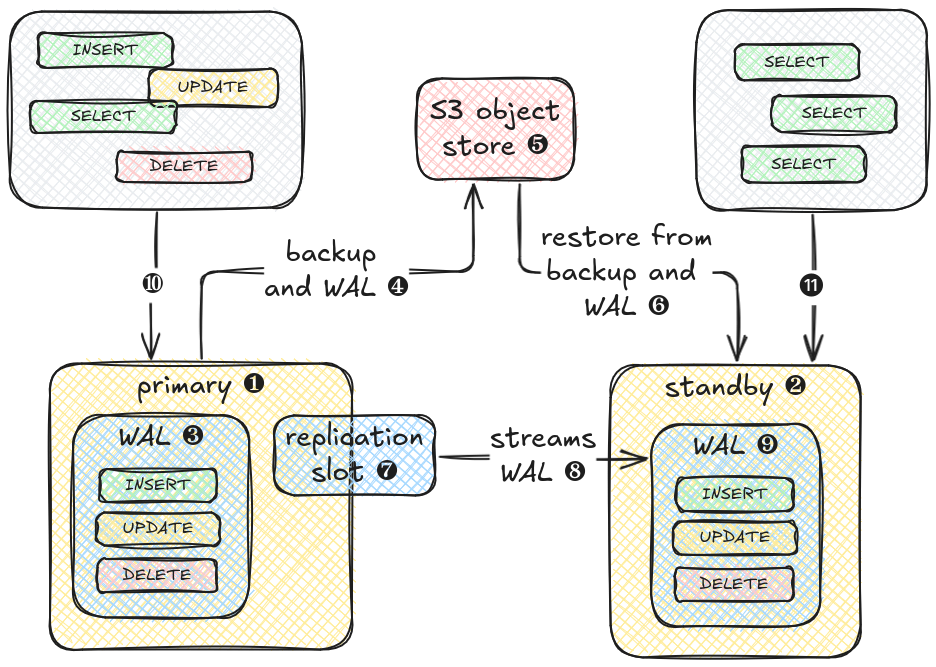
A clustered PostgreSQL setup consists of at least two nodes. The primary ❶ is the leading node for the cluster and also the node capable of answering read and write requests ❿. All incoming requests that alter data are stored in the Write-Ahead-Log WAL ❸. The WAL is divided into small segments that are continously transferred ❹ to an S3 compatible backup location ❺ along with the database data from full or incremental backups. When a standby ❷ node is created it retrieves all backup data from the S3 bucket ❻ and replays the received WAL segments on top of it. When the latest WAL segment is reached, it attaches to the primary’s replication slot ❼ and starts streaming all new WAL segments ❽. The standby node now has all up-to-date data from the primary ❾ and is able to answer read-only requests ⓫.
WAL
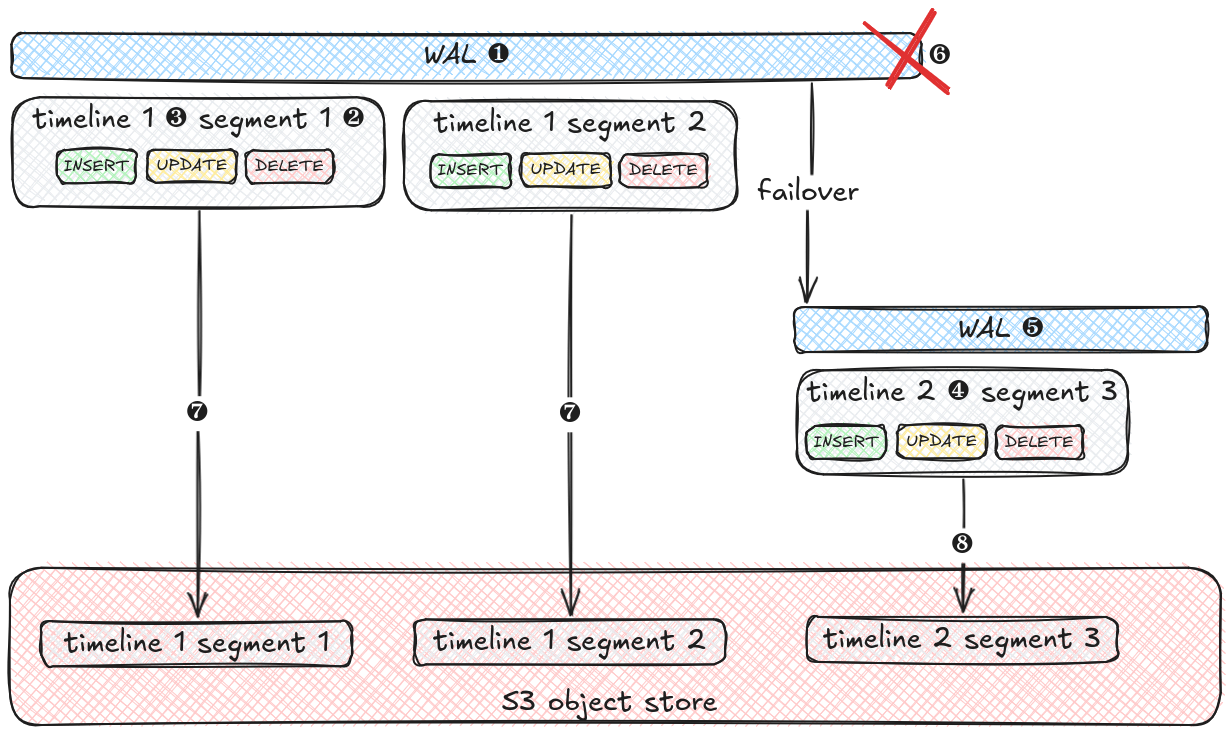
The WAL ❶ stores all data altering operations in a log to be able to replay them in a crash or restore scenario. The WAL is divided into small (16MB) files called segments ❷ that are numbered in ascending order. Each WAL (segment) also has a unique timeline id ❸. When failover happens, e.g. in case of an outage of the primary node, the WAL on the new node ❺ restored from the backup gets a new timeline id ❹ to prevent clashes with WAL segments from the other nodes.
Nodes that are attached to replication slots have to be on the same timeline id as the node offering the replication slot. This is especially important after failover, when a node dies ❻. If the latest WAL segments that were pushed to the backup repository are still from the old node ❼, attaching a node that was restored from this backup to the replication slot of the new node ❺ will fail, because they are on the different timelines. Only when a new backup is pushed from the new node ❽, the backup repository is updated with the new timeline and nodes created form that backup can be attached to the primary again.
Usage
Add Solidblocks RDS collection to Ansible requirements
Apply role to database host group
Additional to the common configuration options, the clustered setup also needs
| variable | description |
|---|---|
primary_node | Ansible hostname of the primary node |
private_subnet | IP subnet that is shared by all database nodes |
replicator_password | credentials used to authenticate the standby nodes against to primary node |
Provisioning Flow
flowchart TD
provisioning_start@{shape: circle, label: "provisioning
start"} --> mount_data_device["`ensure **<data_device>** is mounted`"]
mount_data_device --> is_primary{"`is primary node`"}
is_primary -->|yes|data_dir_empty
data_dir_empty{"`is **<data_dir>**
empty`"} -->|yes|restore_available{"`is backup
available`"}
restore_available -->|no|bootstrap_database
restore_available -->|yes|restore["`restore from backup`"]
restore --> wait_for_restore["`wait for recovery finish marker **/tmp/<stanza_name>-recovery-complete**`"]
wait_for_restore --> start_database_recovery["`start database for recovery`"]
start_database_recovery --> wait_for_recovery["`wait until **pg_is_in_recovery()** is **false**`"]
wait_for_recovery --> stop_database_recovery["`stop recovery database`"]
data_dir_empty -->|no|start_database["`start database`"]
bootstrap_database["`initialize **<data_dir>** with **<superuser_*>** credentials`"] --> start_database
stop_database_recovery --> start_database
start_database --> stanza_exists{"`backup
stanza
exists`"}
stanza_exists -->|yes|create_replication_user
stanza_exists -->|no|stanza_create["`create backup stanza`"]
stanza_create --> create_replication_user["`creation replication user`"]
create_replication_user --> provisioning_finished@{shape: stadium, label: "provisioning finished"}
is_primary -->|no| wait_provisioning_finished["`wait for provisioning
to finish on primary`"]
wait_provisioning_finished --> restore_from_backup["`restore node from
primary backup`"]
restore_from_backup --> config_standby["`configure standby with **primary_conninfo**
pointing to primary node`"]
config_standby --> pg_pass["`add replication credentials to **.pgpass**`"]
pg_pass --> start_standby["`start database`"]
start_standby --> provisioning_finished